What Netflix knows about you and why it's a lesson to others...
$ grep -n "^##" what-netflix-knows-about-you.md

Math.random()), or simply may not capture it in a useful form. Therefore when it comes to connecting these data-points back to something that can measure the success of the recommendations - it gets a little tricky. "No problem!" they might say, we can always conduct (subjective) user satisfaction surveys. It doesn't matter if you are serving video content, news articles or adverts .. this is known (in the biz) as #FAIL If you do nothing else right, you absolutely must capture data about what was served to customers.
Measuring User Activity
Measuring user activity is key So your swanky recommendation system is surfacing what you think is relevant content, but how do you determine if the user even saw your suggestions - let alone interacted with them. This is the interesting part, and I find it fascinating that so many implementations only appear to measure Click-through's or Purchases. The fact of the matter is that if the content recommended was in-front of the user, they've already interacted with it in an implicit way - you just need to figure it out. 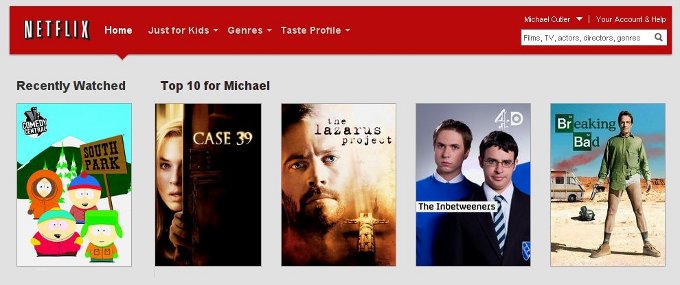
Tracking Implicit Interactions
esn=null&country=GB&application_name=MERCHWEB&application_v=1.2&data=[
{"time":1340138780754,"request_id":"4fc...019","video_id":70095139,"track_id":50000085,"row":0,"rank":6,"location":"WATCHNOW"},
{"time":1340138780754,"request_id":"4fc...019","video_id":60020817,"track_id":50000085,"row":0,"rank":7,"location":"WATCHNOW"},
{"time":1340138780754,"request_id":"4fc...019","video_id":70139996,"track_id":50000085,"row":0,"rank":8,"location":"WATCHNOW"},
{"time":1340138780754,"request_id":"4fc...019","video_id":70213047,"track_id":50000085,"row":0,"rank":9,"location":"WATCHNOW"},
{"time":1340138780754,"request_id":"4fc...019","video_id":70102778,"track_id":50000085,"row":0,"rank":0,"location":"WATCHNOW"},
{"time":1340138780754,"request_id":"4fc...019","video_id":70105820,"track_id":50000085,"row":0,"rank":1,"location":"WATCHNOW"}]
This is an example of the ping sent from my browser a moment ago, its quite clear to see 'video_id', 'row' and 'rank' going back to be processed and recorded by Netflix. Just to re-iterate this point, I haven't clicked any mouse button - I simply hovered over the right/left arrows to scroll around the UI. This sort of activity wouldn't be captured by Clickstream or Web Logs, it has to be engineered into the User Interface.
Capturing Implicit Activity Data
Implicit user activity data is King If all you are capturing is click-throughs and transactions - you are missing most of the data. Going a step beyond the scenario illustrated above, say I've browsed around a few genres, picked something and clicked 'Watch Now'. Is that the end of the story? No! The next step up in data collection is capturing how users interact with your content - I will stick with the Netflix example for now. Most web browsers, smart phones and application platforms allow you to tightly control and monitor their video playback widgets. You can capture details like:
- Is the content playing, or is it paused?
- How far through the content are they?
- Is the video widget having buffering problems?
- Is the video widget playing anything at all?
- Is the user fast-forwarding through sections of the content?

Again, most video content on the internet is delivered over Content Delivery Networks (CDN), inferring this sort of activity from CDN logs is not impossible but its right up there with Cold Fusion and Faster-than-Light space travel. It makes far more sense to build this measurement into the application, be it a web-based application, smart phone app or some monolithic Flash/Silverlight application.
Processing Big Data at Scale
Holy cr@p, we've now got 200TB of implicit activity data!?!?! Firstly, congratulations! You've overcome the first hurdles and are now merrily collecting a potential gold-mine of data. Now comes the hard part, making sense of it all! This is the area where you need a bit of a head for statistics, and a set of tools that help you 'discover' trends in behaviours, build 'models' based on the captured data and start to make 'predictions'. This isn't a particularly new field, it's existed in one form or another for decades. At the moment the skills and people capable of doing these things are gravitating around the name "Data Scientists". So what is a Data Scientist? The best description I've seen comes from @josh_wills (Data Scientist @ Cloudera): 
The Future of Data Science
Summary It comes as no surprise to me that Netflix, Facebook, Google etc. all collect masses of data - "Massive Data" even - it is core to their businesses. Traditional enterprises are now struggling to catch-up. Consultancies, software vendors large and small are all eager to jump on the bandwagon and sell you just about anything they can get away with branding 'Big Data'. However it's important to note, that you can have all the shiny 'Big Data' plumbing you like with connectors to just about every other appliance you already have - none of this will help you solve your real-world business challenges. If 2012 is the year of 'Big Data', then 2013 will almost certainly become the year of 'Data Science'. I'm sorry guys, but if you are in the 'Big Data' space, it's already heavily commoditized by services like Amazon Elastic Map/Reduce - and it's only going to get more-so. Solving problems in new and innovative ways is what's needed - it's what I'm doing! Thanks for reading! Feel free to engage in discussion in the comments below or on Twitter (@cotdp). If some of the points raised in this post hit a little close to home… it’s not too late to contact us at TUMRA - we're a Data Science agency and I'm its CTO.
$ subscribe --newsletter
Practical AI engineering, in your inbox
Field notes for technical leaders building agents, evaluation systems, governance, and production infrastructure.
Related
I Built a $0 Tool That Saves Hours of AI Training Prep (And You Can Too)
At 3 AM, I was manually cropping 47 personal photos for a LoRA model when I realized half were the wrong aspect ratio. Three hours wasted. So I built a simple Python app that does the same work in 15 minutes—and it changed how I think about AI tooling infrastructure.
Tools, Then Teammates, Then Autonomy — Part 2: The Autonomy Gate
Clearing the wall: what Phase 3 autonomy actually looks like, the regulatory gate that turns out to be the design, and the two gates that tell you when you're allowed to move.
Tools, Then Teammates, Then Autonomy — Part 1: Hitting the Wall
Becoming AI-native is an ordered path you walk one pipeline at a time — tools, then teammates, then autonomy. Part 1: codifying the process, the assist layer, and the wall every pilot dies at.